Overview
This repository contains the beta version of the RAG implementation of the paper (provisional title) “Provisional title: AI-Driven Text Analysis in the Political Economy of Sustainability: Hybrid Retrieval-Augmented Generation and LLM Multi-Agent Approach.”
By Bastián González-Bustamante and Natascha van der Zwan.
Document Parsing
Docling Selection
We experimented with a number of PDF parsing methods, including Pdftools, Pdfplumber, PyMuPDF, Pdfminer, Apache Tika, and Docling. Docling was selected due to its superior performance, consistently balancing precision, comprehensiveness and structural accuracy. However, it is necessary to revisit the picture processing step.
This step allows us to annotate different pictures that appear in the reports as a separate captioning task. We are running additional experiments to reinforce this task using Visual Large Models (VLMs) since this involves considerable trade-offs between performance and computing time.
VLMs Captioning Progress
 |
 |
Model Selection Benchmark
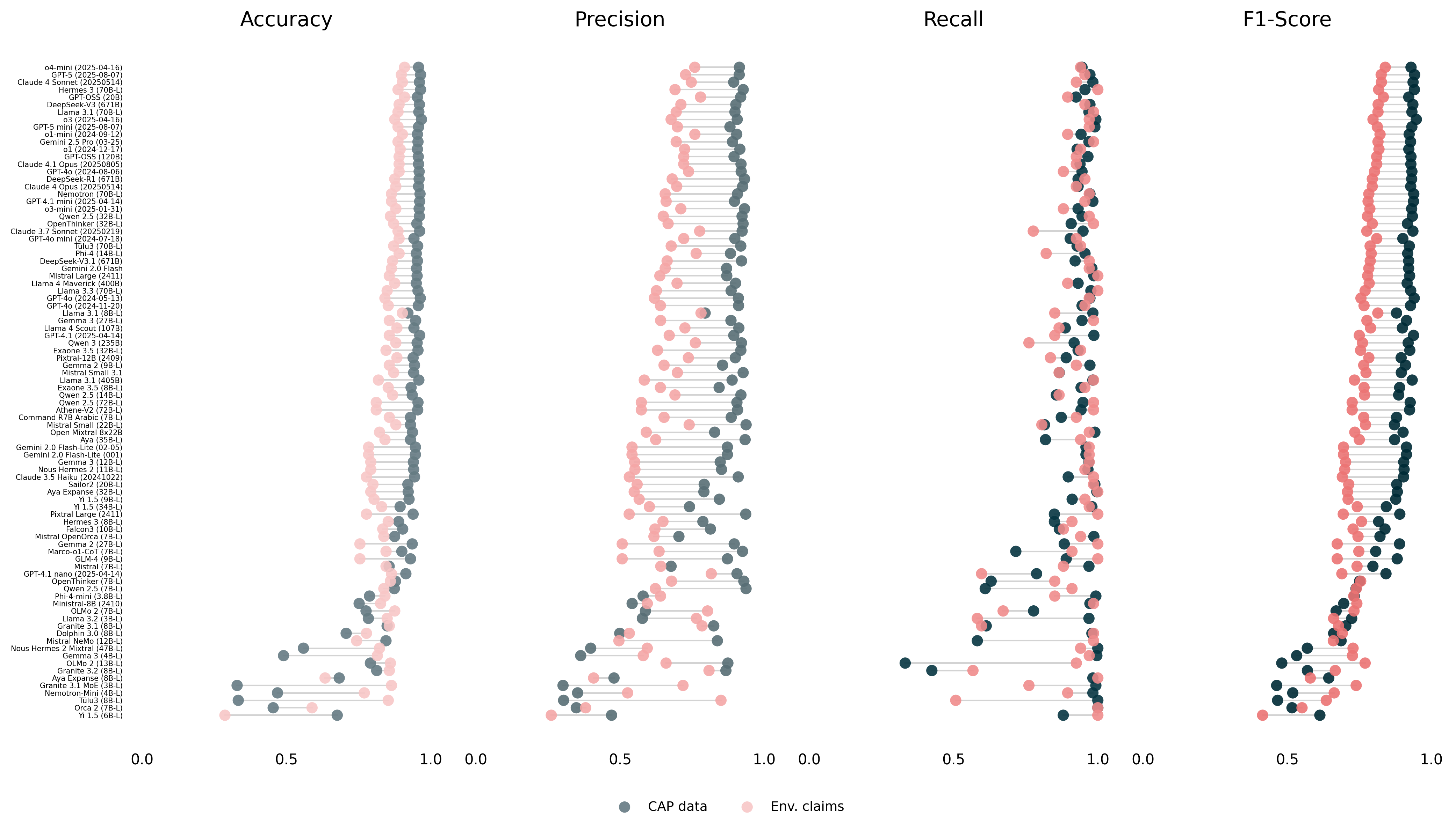
Multi-Agent RAG Orchestration
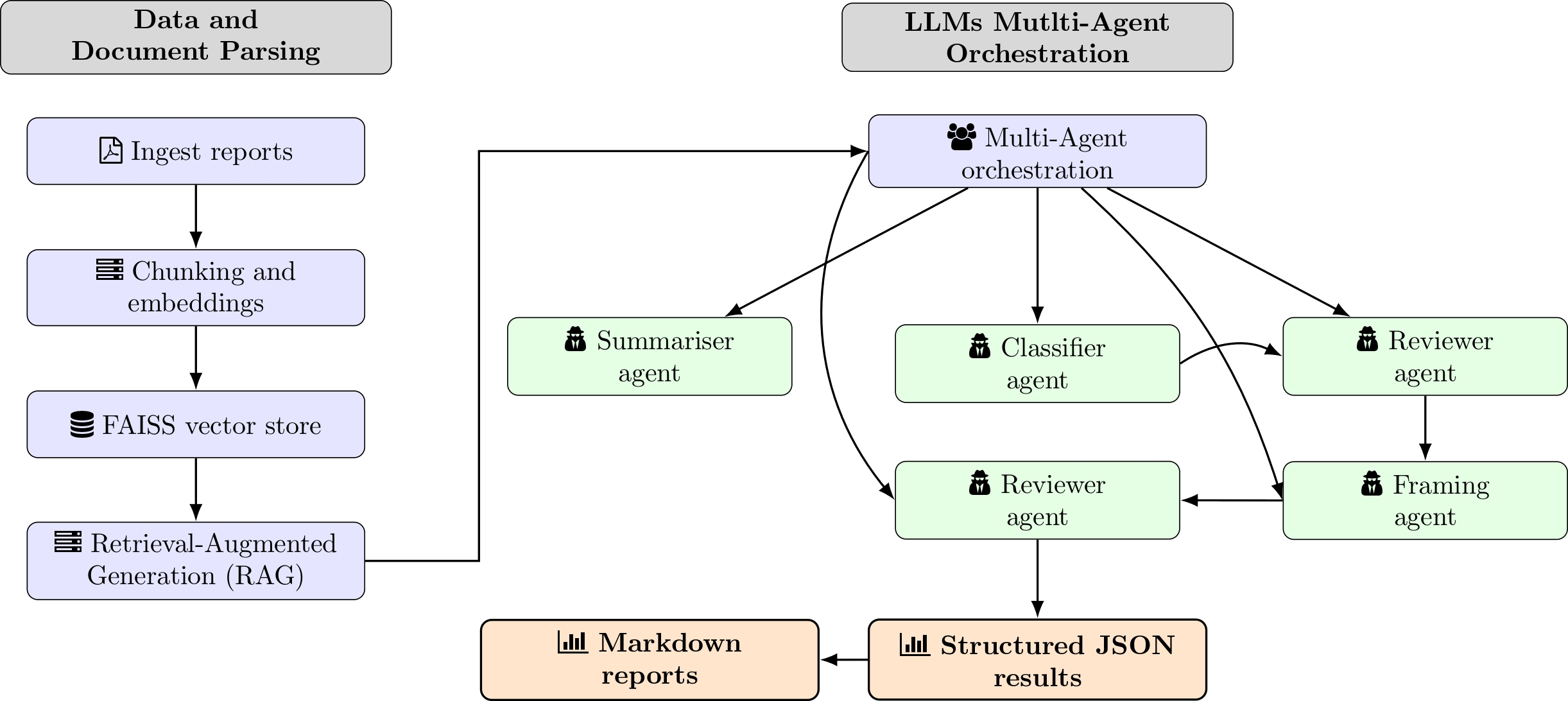
Note. Frame was replaced by classic stance detection.
Results
The selection of models was based on the benchmark above. We are using a fully open-source pipeline in which Llama 3.1 (70B) prepare the summary, GPT-OSS (20B) makes the decisions and Hermes 3 (70B) reviews and overturns with RAG-fed evidence. For robustness checks, we will rely on a mixed pipeline in which Llama 3.1 will be replaced by GPT-5-mini and Hermes 3 by GPT-5, both state-of-the-art closed, flagship OpenAI models.
We will introduce human-in-the-loop revision based on consistency metrics between both pipelines.
Open-Source Pipeline
- Summariser:
llama3.1:70b - Classifier:
gpt-oss:latest - Reviewer (presence):
hermes3:latest - Framing:
gpt-oss:latest - Reviewer (framing):
hermes3:latest - Embeddings:
text-embedding-3-large
Mixed-Pipeline
- Summariser:
gpt-5-mini-2025-08-07 - Classifier:
gpt-oss:latest - Reviewer (presence):
gpt-5-2025-08-07 - Framing:
gpt-oss:latest - Reviewer (framing):
gpt-5-2025-08-07 - Embeddings:
text-embedding-3-large
Batches
Reports now include: (1) captioning process with VLM to improve picture descriptions; (2) improved retrieval context by adjusting chunk size and overlap to limit semantic dilution and increasing the number of retrieved neighbours (k) to improve coverage of concept-relevant passages; (3) frame was replaced by classic stance detection; and (4) prevalence is now reporting share of sentences which could be used to get raw estimates based on documents’ lenght. We are also now using the original languages, taking advantage of LLMs’ multilingual capabilities.
| Batch-01 | Batch-02 | Batch-03 | Batch-04 | Batch-05 |
 |
|
|
|
|
| Batch-06 | Batch-07 | Batch-08 | Batch-09 | Batch-10 |
|
|
|
|
|
Note. Progress is considering missing observations as already processed. There could be some delay between processed reports and preliminary plots. Also, it could be helpful to reset the browser cache from time to time.
Preliminary Plots
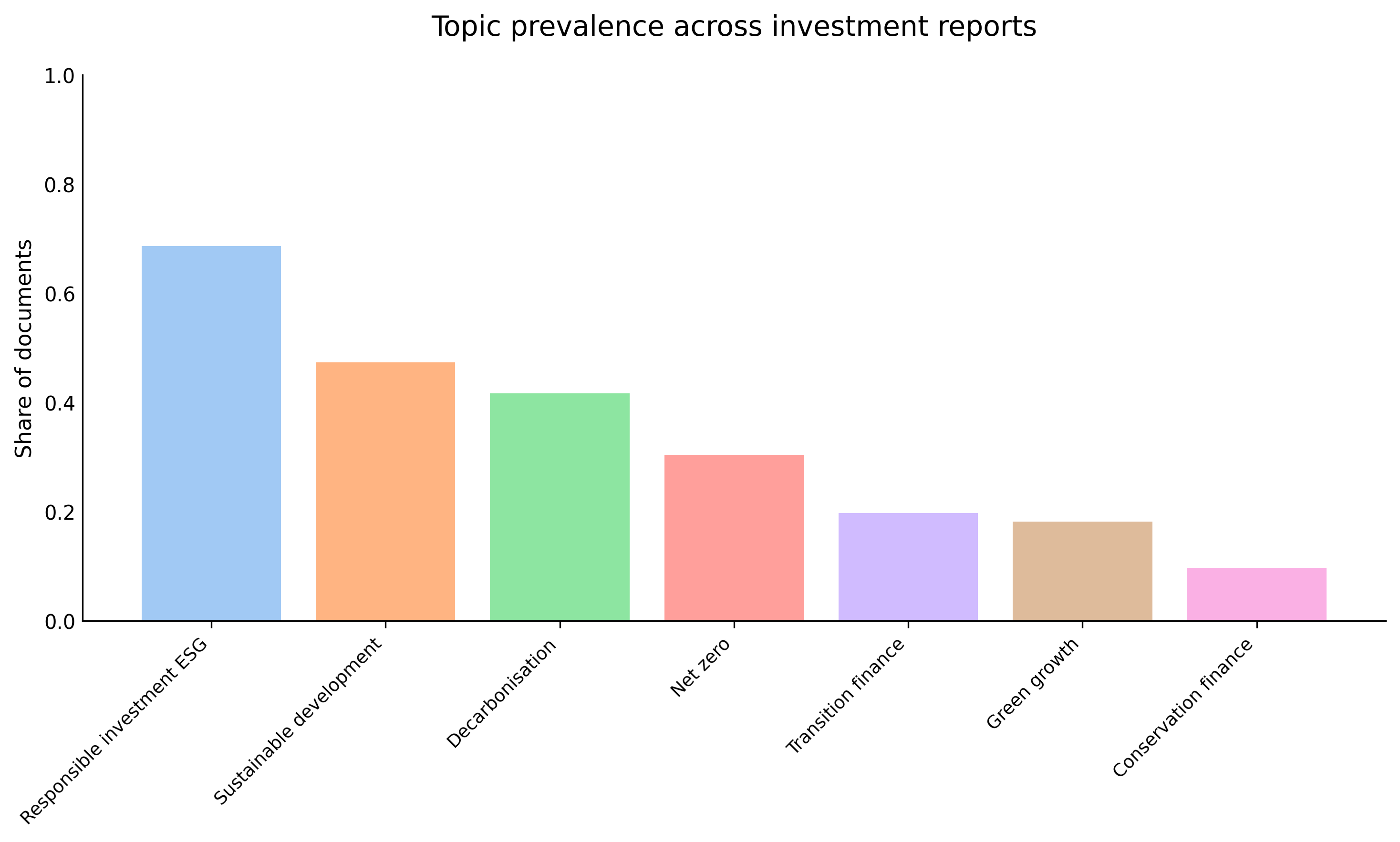
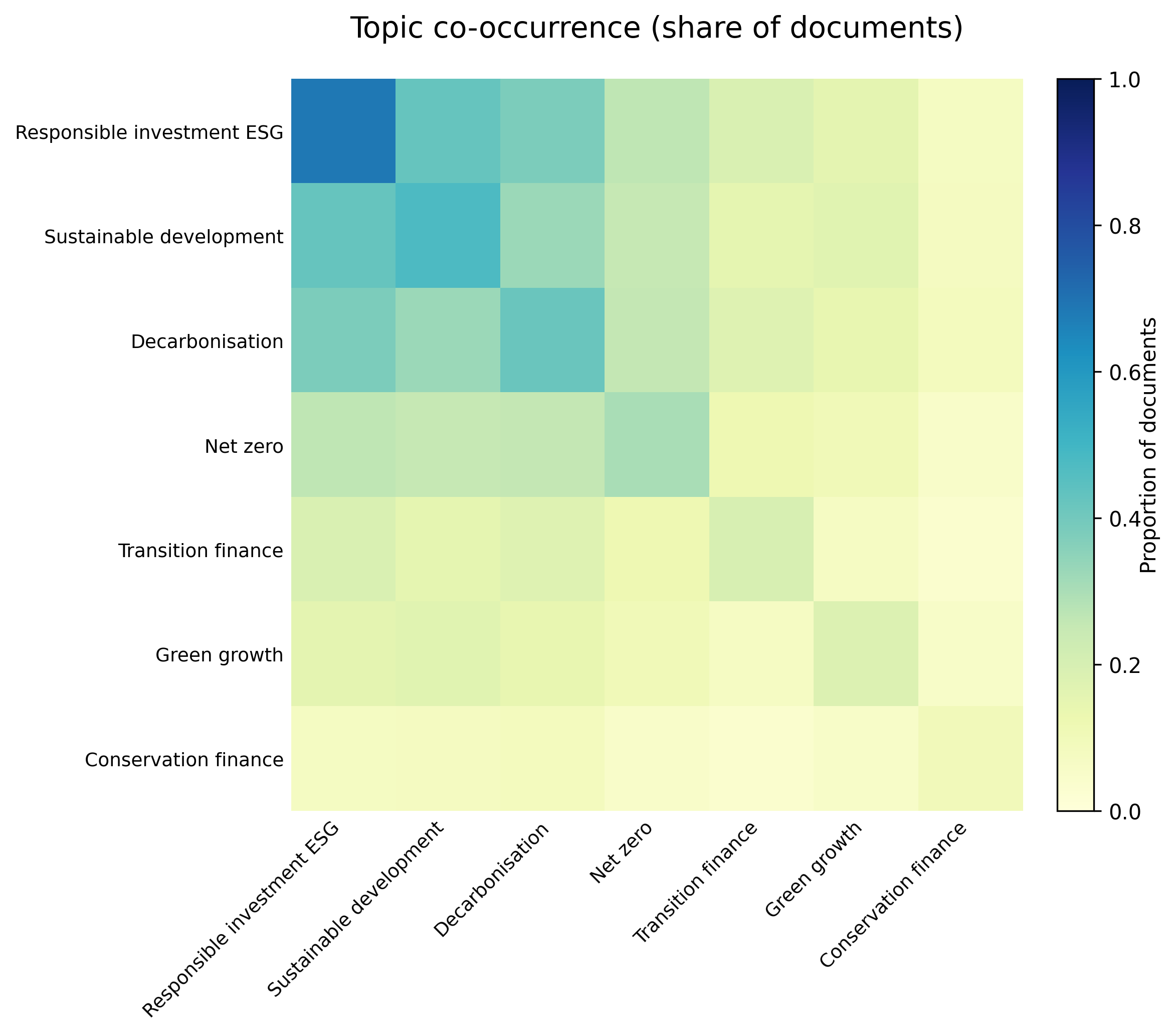
Validation
Based on the adjustments logs and JSON files, we have detected 75 RAG reports that need manual validation so far. Further manual and automated validation will be carried out.
Latest update: January 20, 2026.